Performance_artist
Table of Contents
出题人****
题目描述
Performance artist released his new work: handwriting HEX characters on paper to remind people that this gorgeous flag should reside in their memory instead of a stream of 0s and 1s.
题目附件: 点击下载附件 1
Hint: Dataset: numbers MNIST,letters EMNIST
解
首先让我们看看图片:
➜ ab9afbbab77549ef94c31f515fce5d53 exiftool attachment.png
ExifTool Version Number : 10.80
File Name : attachment.png
Directory : .
File Size : 153 kB
File Modification Date/Time : 2020:07:16 22:22:11+08:00
File Access Date/Time : 2020:08:02 02:13:51+08:00
File Inode Change Date/Time : 2020:08:01 11:31:38+08:00
File Permissions : rwxrwxrwx
File Type : PNG
File Type Extension : png
MIME Type : image/png
Image Width : 896
Image Height : 504
Bit Depth : 8
Color Type : Grayscale
Compression : Deflate/Inflate
Filter : Adaptive
Interlace : Noninterlaced
Image Size : 896x504
Megapixels : 0.452
这眼熟的分辨率真是让人激动不已啊

什么?你看不到图片?不用担心,这是正常的————你可以右键另存为自己看一下
让我们把它转换成正常一点的 RGB 图片:

这眼熟的字体同样令人激动不已,ML DL 选手是不是蠢蠢欲动了呢
由于本人不是机器/深度学习人,就从 Kaggle 上随便找了一个基于 tensorflow 的 EMNIST 的 model (你可能需要登录)
切分图片
为了识别,我将图片重新切分成 28 * 28 的正方形,并且由 RGB 数值生成对应的灰度图:
from PIL import Image
base_img_path = "./boom.png"
base_img = Image.open(base_img_path)
mnist_size = 28
char_column_count = int(base_img.size[0] / mnist_size)
char_row_count = int(base_img.size[1] / mnist_size)
processed_img_set = []
for y in range(0, char_row_count):
for x in range(0, char_column_count):
# Returns a copy of a rectangular region from the current image.
# The box is a 4-tuple defining the left, upper, right, and lower pixel coordinate.
temp_img = base_img.crop((x * 28, y * 28, (x + 1) * 28, (y + 1) * 28))
processed_img_set.append(temp_img)
# x is horizontal
# y is vertical
def get_img(x: int, y: int) -> Image:
return processed_img_set[y * char_column_count + x]
processed_img_numpy = []
for y in range(0, char_row_count):
for x in range(0, char_column_count):
temp = np.zeros((28, 28))
for yy in range(0, 28):
for xx in range(0, 28):
temp[yy][xx] = get_img(x, y).getpixel((xx, yy))[0]
processed_img_numpy.append(temp)
# x is horizontal
# y is vertical
def show_numpy_img(x: int, y: int):
plt.imshow(processed_img_numpy[x * char_column_count + y], cmap='gray')
plt.show()
进行测试:
show_numpy_img(0, 3)
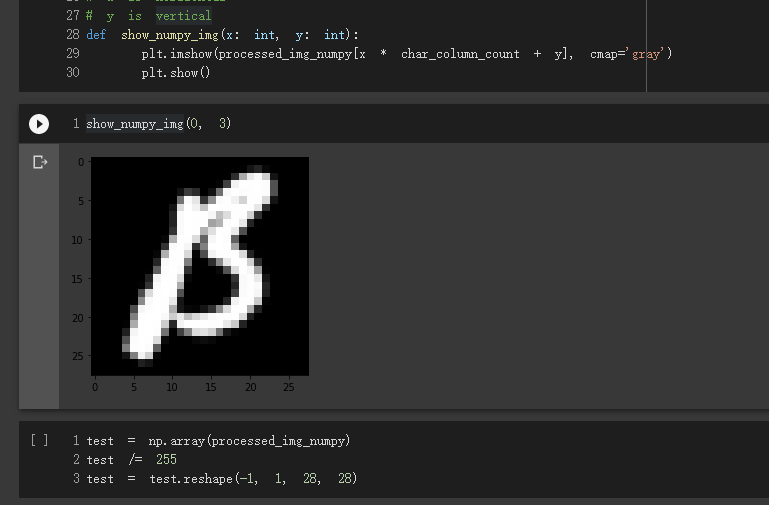
识别(MNIST)
test = np.array(processed_img_numpy)
test /= 255
test = test.reshape(-1, 1, 28, 28)
# show shape
>>> test.shape
<<< (576, 1, 28, 28)
# compare with original
>>> X_test.shape
<<< (5000, 1, 28, 28)
test_placeholder = np.zeros(len(processed_img_numpy))
result = ""
# This network trained by Marshmallow has an original batch_size of 96.
# # feed 96 examples to network at one time
# batch_size = 96
batch_size = 8
test_mini_batches = [test[k:k + batch_size] for k in range(0, len(test), batch_size)]
test_placeholder_mini_batches = [test_placeholder[k:k + batch_size] for k in range(0, len(test_placeholder), batch_size)]
for idx, (X_batch, what) in notebook.tqdm_notebook(enumerate(zip(test_mini_batches, test_placeholder_mini_batches)),
total = len(test_mini_batches),
leave = False):
layer1_out, layer1_cache = conv_relu_pool_forward(X_batch, weight_1, bia_1, **layer1_parameter)
layer2_out, layer2_cache = fc_forward(layer1_out, weight_2, bia_2)
layer3_out, layer3_cache = relu_forward(layer2_out)
layer4_out, layer4_cache = fc_forward(layer3_out, weight_3, bia_3)
loss, pred, dloss = softmax_loss(layer4_out, y_batch)
for i in np.argmax(pred, axis=1):
result += str(i)
>>> result
504003041400000008000893515088039007280000002401000008000000656361673574789475504605823010089370877129505027035683037181523148156951528090171889562526932717680708965800256868978273162250168155615557697869697505830084768997863905416268524340451795034105055565984489012185925898279876565081580392066668059917499311322586328007328855031033331066084093904195972419341290731406749621065833900258508963492902504693328591631670100323510686427407084138195177181658503398057479893615144866815308315078850519293464640250460101150014000900080035936550860390071800000068010000080024000000
识别(EMNIST)
test = np.array(processed_img_numpy)
test /= 255
test = test.reshape(-1, 28, 28, 1)
def run_prediction_test(idx):
_result = np.argmax(model.predict(test[idx:idx+1]))
return str(class_mapping[_result])
>>> X_test.shape
<<< (18800, 28, 28, 1)
>>> print(type(X_test))
print(type(X_test[0]))
print(type(X_test[0][0]))
print(type(X_test[0][0][0]))
print(type(X_test[0][0][0][0]))
print(X_test[0][0][0])
print(X_test[0][0][0][0])
<<< <class 'numpy.ndarray'>
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
<class 'numpy.float64'>
[0.]
0.0
# compare with original
>>> test.shape
<<< (576, 28, 28, 1)
>>> print(type(test))
print(type(test[0]))
print(type(test[0][0]))
print(type(test[0][0][0]))
print(type(test[0][0][0][0]))
print(test[0][0][0])
print(test[0][0][0][0])
<<< <class 'numpy.ndarray'>
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
<class 'numpy.float64'>
[0.]
0.0
result = ""
for i in range(len(test)):
result += run_prediction_test(i)
# formatted display
result_str_batches = [result[k:k + char_column_count] for k in range(0, len(result), char_column_count)]
for i in result_str_batches:
temp = ""
temp_batches = [i[j:j + 2] for j in range(0, len(i), 2)]
for ii in temp_batches:
temp += (ii + " ")
print(temp)
5O 4B O3 ON IY DO O0 0O O8 DO DB t3 CI 50 fE OZ
OO OJ d8 OO DO OD df OL OO OO O8 OO OO OO 4E 6C
61 OY ge t4 V8 04 75 SD 4b OE 82 3O 1O DD t3 7O
In ML da CC BO a7 Od I6 Bd D3 X1 IL Sa g1 48 hC
h4 I1 Cf eD tD IJ Lt gY CO ZE 26 a3 d7 fJ 6B bt
De 4f C8 O0 ZE 6e fS eY R2 9Z Ih d2 eO If BL CE
6d tI E7 6g t2 et ba Xb O5 83 AC eP tb 8Y P7 B6
eY OE AL ta 6e ea 4Q AD 45 17 ae Cd d1 CS CC Fb
6b 4M a4 gq C1 21 tC a2 b8 ag tY gd Y6 5F CC Bh
58 CC q2 Ob 66 fg CE Fq 17 44 q3 L1 32 2F 8f JZ
BB a7 C2 8I CS Ae LD 3g 33 LO 6E DI 4O 4d aC 41
qf YJ Z4 LA Bh 12 aO D3 14 ab ZA Yt 2L O6 b8 de
aD D2 tA CC ta b3 4Y 2Y O2 5r 46 AY 3f E5 eL d3
1b 7g 10 Ot 23 B1 Ab ee 4a 7A O7 0g tL Sa IY eL
7t LX 16 5F 5D Ze tZ DI On 7A 8P 36 d5 L4 4b 66
tL 5a ae gL 5O tI fS eI LA Zq J4 ta ft 0Z SO 4b
0L 0I 1F OO 14 OO OY OO O8 OD db 4S L5 50 g6 03
tO OO dI OD OD O0 Lt OL 0O 0O Dg 0O 2t OO OO OO
分析文件
看到开头几个字节发现事情已经很明显了,这是个 Zip archive。所有出现的字符都是 hexidecimal 的。
但很可惜,网络的准确度不会是 100%,特别是 EMNIST 的。
而且 nmd 这字符谁看得清(从下往上第五行,从左往右第四列)

你是 λ?
分析图片
仔细观察图片,可以看到从下往上第三,四行;从左往右第十六列

这要是训练了一个 GAN 去生成应该也不会生成一模一样的吧?
我有充分理由认为这人就是由原字符按照 label 随机挑选了这些数据出来拼合出这一张图
寻找原字符(MNIST)
from google.colab import drive
drive.mount('/content/drive')
import numpy as np
from PIL import Image
import sklearn
import matplotlib.pyplot as plt
import math
from functools import reduce
import torch
import torchvision
from tqdm import notebook
# load data
data = np.load('/content/drive/My Drive/DeepLearningAssiginments/assignment3-cnn/mnist.npz')
X, y, X_val, y_val, X_test, y_test = data['X'], data['y'], data['X_val'], data['y_val'], data['X_test'], data['y_test']
y_alt = y
# original: [0, 255]
# after: [0, 1]
X /= 255
X_val /= 255
X_test /= 255
# reshape the image data to the format (batch_size, channel, height, width)
X = X.reshape(-1, 1, 28, 28)
X_val = X_val.reshape(-1, 1, 28, 28)
X_test = X_test.reshape(-1, 1, 28, 28)
"""
loads boom.png
"""
test = np.array(processed_img_numpy)
test /= 255
test = test.reshape(-1, 1, 28, 28)
result = ""
for tester_idx in range(len(test)):
found = False
for testee_idx in range(len(X)):
tester = test[tester_idx]
testee = X[testee_idx]
if (tester == testee).all():
# print(str(divmod(tester_idx, 32)) + ": " + str(y_alt[testee_idx]))
found = True
result += str(int(y_alt[testee_idx]))
break
if not found:
result += "F"
second_result = ""
for tester_idx in range(len(test)):
if result[tester_idx] != 'F':
second_result += result[tester_idx]
continue
found = False
for testee_idx in range(len(X_val)):
tester = test[tester_idx]
testee = X_val[testee_idx]
if (tester == testee).all():
# print(str(divmod(tester_idx, 32)) + ": " + str(y_alt[testee_idx]))
found = True
second_result += str(int(y_val[testee_idx]))
break
if not found:
second_result += "F"
third_result = ""
for tester_idx in range(len(test)):
if second_result[tester_idx] != 'F':
third_result += second_result[tester_idx]
continue
found = False
for testee_idx in range(len(X_test)):
tester = test[tester_idx]
testee = X_test[testee_idx]
if (tester == testee).all():
# print(str(divmod(tester_idx, 32)) + ": " + str(y_alt[testee_idx]))
found = True
third_result += str(int(y_test[testee_idx]))
break
if not found:
third_result += "F"
result_str_batches = [third_result[k:k + char_column_count] for k in range(0, len(third_result), char_column_count)]
for i in result_str_batches:
temp = ""
temp_batches = [i[j:j + 2] for j in range(0, len(i), 2)]
for ii in temp_batches:
temp += (ii + " ")
print(temp)
print(third_result)
504F03041FF000000800FF9FFF50F6F39007F8000F0FFF01F00008000000666F61672F747874F5504F0F823010FF9F70877FFFFFF0270F5FFF0371815F9148FFF9F1FFFF9FF71F89F62F26F3F7F76FF7FF9FF80F2F6F68FF82F326F2F01F81FF6F55F76972F9FF7FFFF3FFFFFF89FFF6F9FFF16FFFF2439F45F7FFFFF1F5FFFF6F9FF48FF1218F92F898779F765FFFFF58FF920F6662FFFF1F499311F2258F32FFF7F288FFFF103133106608409FFFF19F77241F3412907814FF7F922106F8FFFFF25FFF8F634929025F46FF3FF5F1F3167FF00323FFFFFF4F7F07F8413F19F17718165F5FFF73F5777F8F36F5144F66315FFF315078F5F5FF29246FF402504F0102FF001F000900F800FF93F55F86F39007F8000000FF0100000800F40F0000
寻找原字符(EMNIST)
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from tensorflow import keras
import matplotlib.pyplot as plt
!rm -rf input
!mkdir input
!cd input && wget https://sirius.anzupop.com/upload/emnist-byclass-train-csv.zip
<<< --2020-08-01 16:22:39-- https://sirius.anzupop.com/upload/emnist-byclass-train-csv.zip
Resolving sirius.anzupop.com (sirius.anzupop.com)... 172.67.157.46, 104.27.163.253, 104.27.162.253, ...
Connecting to sirius.anzupop.com (sirius.anzupop.com)|172.67.157.46|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 239821239 (229M) [application/zip]
Saving to: ‘emnist-byclass-train-csv.zip’
emnist-byclass-trai 100%[===================>] 228.71M 18.5MB/s in 13s
2020-08-01 16:22:52 (17.7 MB/s) - ‘emnist-byclass-train-csv.zip’ saved [239821239/239821239]
!cd input && unzip ./emnist-byclass-train-csv.zip
<<< Archive: ./emnist-byclass-train-csv.zip
inflating: emnist-byclass-train.csv
!ls input
<<< emnist-byclass-train.csv emnist-byclass-train-csv.zip
train_data_path = './input/emnist-byclass-train.csv'
# 10 digits, 26 letters, and 26 capital letters that are different looking from their lowercase counterparts
num_classes = 10 + 26 + 26
img_size = 28
def img_label_load(data_path, num_classes=None):
data = pd.read_csv(data_path, header=None)
data_rows = len(data)
if not num_classes:
num_classes = len(data[0].unique())
# this assumes square imgs. Should be 28x28
img_size = int(np.sqrt(len(data.iloc[0][1:])))
# Images need to be transposed. This line also does the reshaping needed.
imgs = np.transpose(data.values[:,1:].reshape(data_rows, img_size, img_size, 1), axes=[0,2,1,3]) # img_size * img_size arrays
labels = keras.utils.to_categorical(data.values[:,0], num_classes) # one-hot encoding vectors
return imgs/255., labels
# The classes of this balanced dataset are as follows. Index into it based on class label
class_mapping = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
# source data: https://arxiv.org/pdf/1702.05373.pdf
>>> class_mapping[34]
<<< "Y"
X, y = img_label_load(train_data_path)
y_alt = y
print(X.shape)
<<< (697932, 28, 28, 1)
"""
loads boom.png
"""
test = np.array(processed_img_numpy)
test /= 255
test = test.reshape(-1, 28, 28, 1)
result = ""
for tester_idx in range(len(test)):
found = False
for testee_idx in range(len(X)):
tester = test[tester_idx]
testee = X[testee_idx]
if (tester == testee).all():
# print(str(divmod(tester_idx, 32)) + ": " + str(class_mapping[np.argmax(y_alt[testee_idx])]))
found = True
result += str(class_mapping[np.argmax(y_alt[testee_idx])])
break
if not found:
result += "0"
result_str_batches = [result[k:k + char_column_count] for k in range(0, len(result), char_column_count)]
for i in result_str_batches:
temp = ""
temp_batches = [i[j:j + 2] for j in range(0, len(i), 2)]
for ii in temp_batches:
temp += (ii + " ")
print(temp)
<<< 00 0B 00 00 00 00 00 00 00 00 DB 00 c0 00 00 a0
00 00 00 00 00 00 dF 00 00 00 00 00 00 00 00 0C
00 00 00 00 00 00 00 00 0b 00 00 00 00 DD 00 00
00 00 dd 0C B0 00 0d 0b 0d 00 00 00 0a 00 00 Ac
00 00 C0 eD 0D 00 0F 00 C0 0E 00 00 00 F0 0B b0
De 0f C0 0D 0E 0e 00 e0 00 A0 00 d0 e0 0f 00 CE
0d 00 E0 00 00 e0 ba 00 Cc B0 0c ef 0b 00 F0 B0
e0 00 A0 0a 0e e0 00 0D 00 00 0e Cd 00 c0 cC 0b
00 0A a0 00 C0 00 0c 00 b0 00 00 00 00 00 CC Bb
00 cC 00 0b 00 00 C0 F0 00 00 00 00 00 00 0F 00
BB 00 C0 00 00 0e 00 00 00 00 00 00 00 0d aC 00
0F 00 00 0A 00 00 00 00 00 ab 0A 00 00 00 b0 de
d0 D0 0A ec 0a 00 00 00 00 0C 00 a0 00 E0 a0 d0
00 0a 00 00 00 B0 Ab ee 00 0A 00 00 00 0a 00 e0
00 00 00 0F 0D 0e 00 D0 00 00 0e 00 d0 00 0b 00
00 0a aE 00 00 00 F0 e0 0A 00 00 0a f0 00 00 00
00 00 0F 00 00 00 00 00 00 00 d0 00 00 00 00 a0
00 00 d0 00 00 00 df 00 00 00 00 00 00 00 00 00
!cd input && wget https://sirius.anzupop.com/upload/emnist-byclass-test-csv.zip
!cd input && unzip ./emnist-byclass-test-csv.zip
<<< --2020-08-01 17:40:45-- https://sirius.anzupop.com/upload/emnist-byclass-test-csv.zip
Resolving sirius.anzupop.com (sirius.anzupop.com)... 104.27.163.253, 172.67.157.46, 104.27.162.253, ...
Connecting to sirius.anzupop.com (sirius.anzupop.com)|104.27.163.253|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 39986604 (38M) [application/zip]
Saving to: ‘emnist-byclass-test-csv.zip’
emnist-byclass-test 100%[===================>] 38.13M 13.6MB/s in 2.8s
2020-08-01 17:40:48 (13.6 MB/s) - ‘emnist-byclass-test-csv.zip’ saved [39986604/39986604]
Archive: ./emnist-byclass-test-csv.zip
inflating: emnist-byclass-test.csv
test_data_path = './input/emnist-byclass-test.csv'
X_test, y_test = img_label_load(test_data_path)
second_result = ""
for tester_idx in range(len(test)):
if result[tester_idx] != '0':
second_result += result[tester_idx]
continue
found = False
for testee_idx in range(len(X_test)):
tester = test[tester_idx]
testee = X_test[testee_idx]
if (tester == testee).all():
# print(str(divmod(tester_idx, 32)) + ": " + str(class_mapping[np.argmax(y_alt[testee_idx])]))
found = True
second_result += str(class_mapping[np.argmax(y_test[testee_idx])])
break
if not found:
second_result += "0"
print(second_result)
000B0000000000000000DB00c00000a00000d0000000dF00000000000000000C00000e00000000000b0E000000DD00000000ddCCB0000d0bBd0000000a0000Ac0000C0eD0D000F00C00E0000d0F00Bb0De0fC00D0E0e00e000A000d0e00f00CE0d00E00000e0ba0bCcB0Acef0b00F0B0e00EA00a0ee0000D00000eCdd0c0cCFb0b0Aa000C0000c00b000000d000FCCBb00cC000b0000C0F00000000000000F00BBa0C000C0Ae000000000000000daC000F00000A0000000000ab0A000000b0ded0D00Aec0a000000000C00a00fE0a0d0000a000000B0Abee0a0A0000000a00e00000000F0D0e00D000000e00d0000b00000aaE000000F0e00A00000af000000b00000F00000000000000db00C00000a00000d0000000df000000000000000000
Piece them together
result_digits = ***
result_letters = ***
real_result = ""
count = 0
for i in range(len(result_digits)):
if result_digits[i] != 'F':
real_result += result_digits[i]
else:
if result_letters[i] != '0':
real_result += result_letters[i]
else:
real_result += '?'
count += 1
print(real_result)
504B03041??000000800DB9?c?50?6a39007d8000?0?dF01?00008000000666C61672e747874?5504b0E823010DD9?70877?ddCCB0270d5bBd0371815a9148Ac?9?1C?eD9D?71F89C62E26?3d7F76Bb7De9fC80D2E6e68e?82A326d2e01f81CE6d55E76972e9ba7bCcB3Acef?b89F?B6e9?EA16a?ee2439D45?7?eCdd1c5cCFb6b9Aa48?C1218c92b898779d765FCCBb58cC920b6662C?F?1?499311?2258F32BBa7C288C?Ae103133106608409daC?19F77241A3412907814ab7A922106b8ded?D25Aec8a634929025C46a?3fE5a1d3167a?00323B?Abee4a7A07?8413a19e17718165F5D?e73D5777?8e36d5144b66315aaE315078F5e5?A29246af402504b0102?F001?000900?800db93C55?86a39007d8000000df0100000800?40?0000
result_str_batches = [real_result[k:k + char_column_count] for k in range(0, len(real_result), char_column_count)]
for i in result_str_batches:
temp = ""
temp_batches = [i[j:j + 2] for j in range(0, len(i), 2)]
for ii in temp_batches:
temp += (ii + " ")
print(temp)
<<< 50 4B 03 04 1? ?0 00 00 08 00 DB 9? c? 50 ?6 a3
90 07 d8 00 0? 0? dF 01 ?0 00 08 00 00 00 66 6C
61 67 2e 74 78 74 ?5 50 4b 0E 82 30 10 DD 9? 70
87 7? dd CC B0 27 0d 5b Bd 03 71 81 5a 91 48 Ac
?9 ?1 C? eD 9D ?7 1F 89 C6 2E 26 ?3 d7 F7 6B b7
De 9f C8 0D 2E 6e 68 e? 82 A3 26 d2 e0 1f 81 CE
6d 55 E7 69 72 e9 ba 7b Cc B3 Ac ef ?b 89 F? B6
e9 ?E A1 6a ?e e2 43 9D 45 ?7 ?e Cd d1 c5 cC Fb
6b 9A a4 8? C1 21 8c 92 b8 98 77 9d 76 5F CC Bb
58 cC 92 0b 66 62 C? F? 1? 49 93 11 ?2 25 8F 32
BB a7 C2 88 C? Ae 10 31 33 10 66 08 40 9d aC ?1
9F 77 24 1A 34 12 90 78 14 ab 7A 92 21 06 b8 de
d? D2 5A ec 8a 63 49 29 02 5C 46 a? 3f E5 a1 d3
16 7a ?0 03 23 B? Ab ee 4a 7A 07 ?8 41 3a 19 e1
77 18 16 5F 5D ?e 73 D5 77 7? 8e 36 d5 14 4b 66
31 5a aE 31 50 78 F5 e5 ?A 29 24 6a f4 02 50 4b
01 02 ?F 00 1? 00 09 00 ?8 00 db 93 C5 5? 86 a3
90 07 d8 00 00 00 df 01 00 00 08 00 ?4 0? 00 00
print("Unknown count: ", count)
<<< Unknown count: 44
最终的拼合文件
看来刚才那个是 2 ,嘿嘿!
剩下的应该自己看看问题也不大
那么我们打开 010 Editor,并且进行猜测:
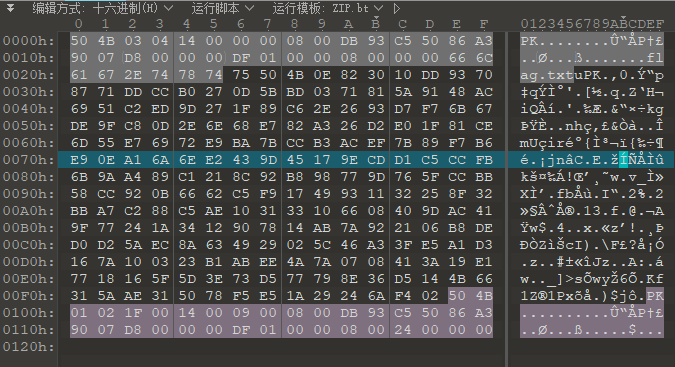
之后使用 WinRAR 修复。(我的猜功真没那么好,也有可能是我数据集不够全)
➜ ab9afbbab77549ef94c31f515fce5d53 unzip ./rebuilt.t.zip
Archive: ./rebuilt.t.zip
inflating: flag.txt bad CRC d7c7fd58 (should be 0790a386)
解压出了 flag.txt:
! n ere is your flag:
https://www.splitbrain.org/services/ook
+++++ ++++[ ->+++ +++++ +<]>+ +++++ .<+++ [->-- -<]>- .<+++ [->-- -<]>-
.<+++ +[->+ +++<] >+.<+ ++[-> ---<] >---- -.<++ +++++ [->++ +++++ <]>++
++.-- --.<+ +++[- >---- <]>-- ----. +++++ +++.< +++[- >---< ]>-.+ ++.++
+++++ .<+++ [->-- -<]>- .+++. -.... --.++ +.<++ +[->+ ++<]> ++++. <++++
++++[ ->--- ----- <]>-- ----- ----- --.<+ +++[- >++++ <]>+. +...< +++++
+++[- >++++ ++++< ]>+++ +++++ +++.. .-.<
即刻复制黏贴:
我个人使用 这个
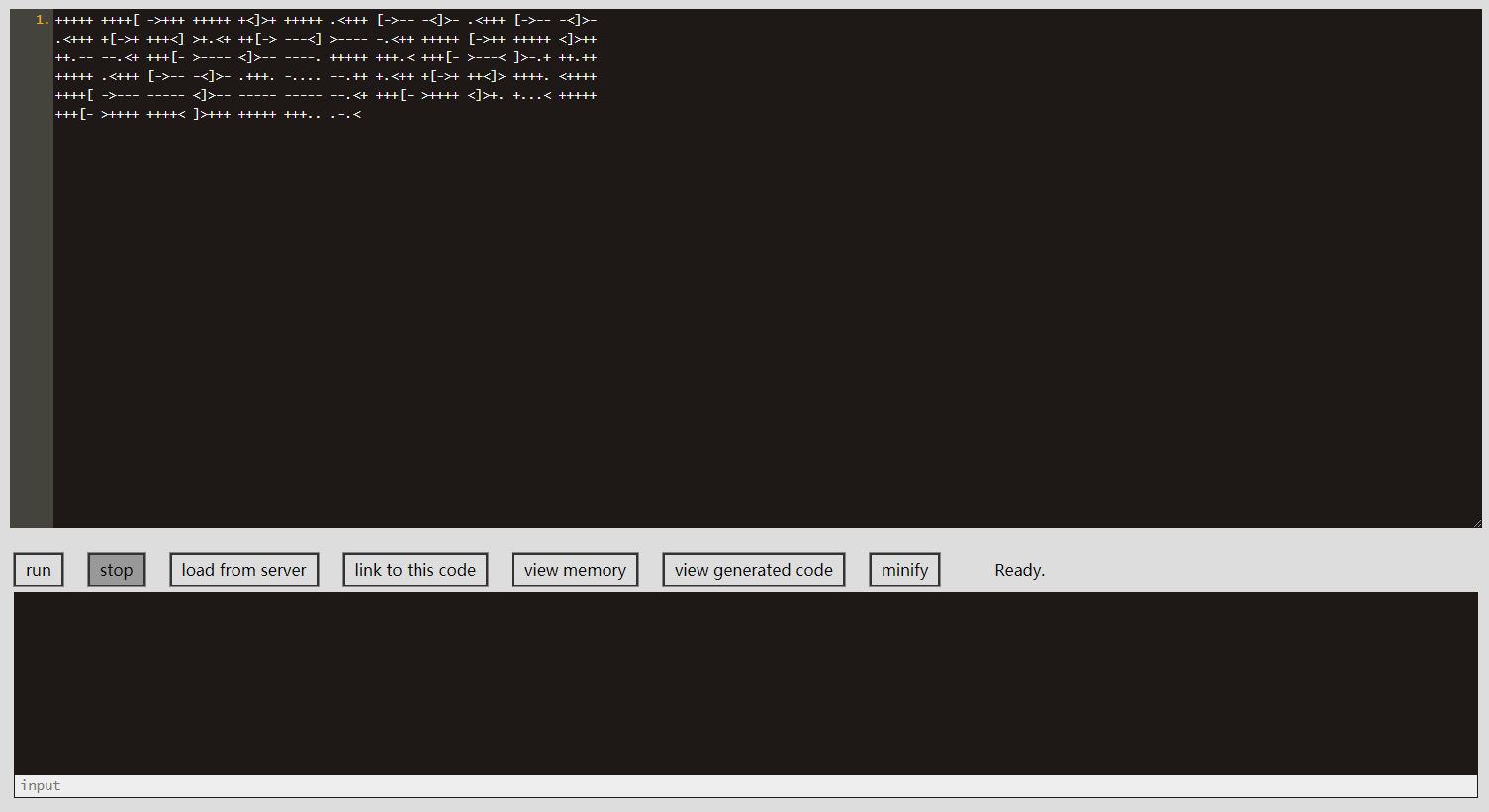
点击 Run,得到结果:
WMCTF{wai_bi_baaaa_bo!2333~~~}
您搁这加密聊天还 2333 呢?
以上。
